Introduction
We previously talked about the impact of AI on software architects, how it can increase their productivity in documenting designs, researching new technologies, and extracting key information from architectural documents. However, AI cannot act as a replacement for software architects; it is only a powerful tool whose limits haven’t been identified yet. Software architects make critical decisions and provide high-quality output based on their domain expertise, business context, and technical depth.
However, as a fun experiment, let’s see if AI can operate as a “software architect” and analyze its performance. We’ll test four LLMs, give each the same set of prompts, evaluate their outputs and diagrams, and share our conclusions at the end. These LLMs are:
- GPT-4o (by ChatGPT)
- Claude 4.0 Sonnet (by Anthropic)
- Sonar (by Perplexity)
- Grok 3 (by xAI)
🏦 Scenario: Banking Recommendation Service
Let’s start with a scenario.
Leadership wants to increase customer engagement by offering personalized banking experiences that help users discover relevant financial products. They ask the engineering team to design an ML-based recommendation service that analyzes user behavior, transaction history, and other signals to suggest tailored products (e.g., credit cards, savings accounts, or investment options). The team has a software architect, who is expected to scope this work and design the architectural diagram that outlines how this new feature should be integrated into the existing banking platform. To accelerate planning, the architect wants to explore whether a large language model (LLM) can assist in generating a high-quality architecture proposal.
Given the scenario, we’ll copy and paste the prompt below into four LLMs using identical follow-up prompts to compare their responses.
Prompt
“You are a software architect tasked with creating C4 diagrams for an ML-based product recommendation service for a bank. We want a new software component that leverages user account behaviour, transaction history, and optional third-party financial signals to generate personalized product recommendations (e.g., savings accounts, credit cards, investment options). This component should be accessible by both internal banking apps and customer-facing channels (web and mobile apps). We call this the Panda Service.
Your role is to create a comprehensive architecture diagram for Panda based on the C4 Model.
Context Diagram: Show how Panda fits into the broader banking system and who interacts with it (e.g., internal services, end users, data providers).
Container Diagram: Break down the Panda system into deployable containers/services (e.g., API layer, model training, model inference, data ingestion).
Component Diagram: Detail the components within each container, such as data pipelines, model serving endpoints, feature extractors, model retrainers, schedulers, etc.
Code Diagram: For a selected component (e.g., model inference service), show class-level or module-level abstractions.
Make sure the design is comprehensive and production-ready, so we can present it to both technical and product leadership for approval and hand it over to developers for implementation. Think through all technical aspects: data flow, interfaces, abstractions, scalability, and monitoring.
As a software architect, your diagrams should capture best practices in system design and conform to banking regulations.”
Observations
We noticed that the responses from the four LLMs tend to fixate on generating the Code diagram, while struggling to produce Context, Container, and Component diagrams. The models did provide key concepts with some explanations such as the banking gateways, data ingestion pipelines, model inferencing, etc. However, they fell short in explaining the reasoning behind their architectural choices. The models also describe the same technology choices for implementing the key concepts like AWS API gateway, SageMaker, PostreSQL, Redis, and S3 in their Container/Component diagrams. It seemed like the LLMs were selecting popular technologies based on patterns seen in other designs, rather than applying contextual logic or reasoning.
We also observed that the LLMs often operated in a “perfect world” setup, designing architecture without any real-world constraints. The designs lacked external factors like technology restrictions, budget limitations, or change of requirements. It seemed easy to corner the LLM and cause it to get stuck when we asked follow-up questions or changed the requirements. 🪦
While the LLMs did identify system actors for the banking system, they failed to account for the engineering team maintaining that system. How should they deploy their code to production, how to roll out newer versions of the recommendation service, or how data should be exported for further analytics.
Based on what we have, here’s our take on LLMs:
- They design software diagrams like junior or mid-level programmers
- They lack pragmatic thinking in architectural decisions
- They assume ideal scenarios and fail to cover edge cases or evolving requirements
TL;DR: we should only trust software architects in their output, not LLMs. 🙅♂️
Here’s a brief analysis of each LLM’s performance.
1. GPT-4o (by ChatGPT)
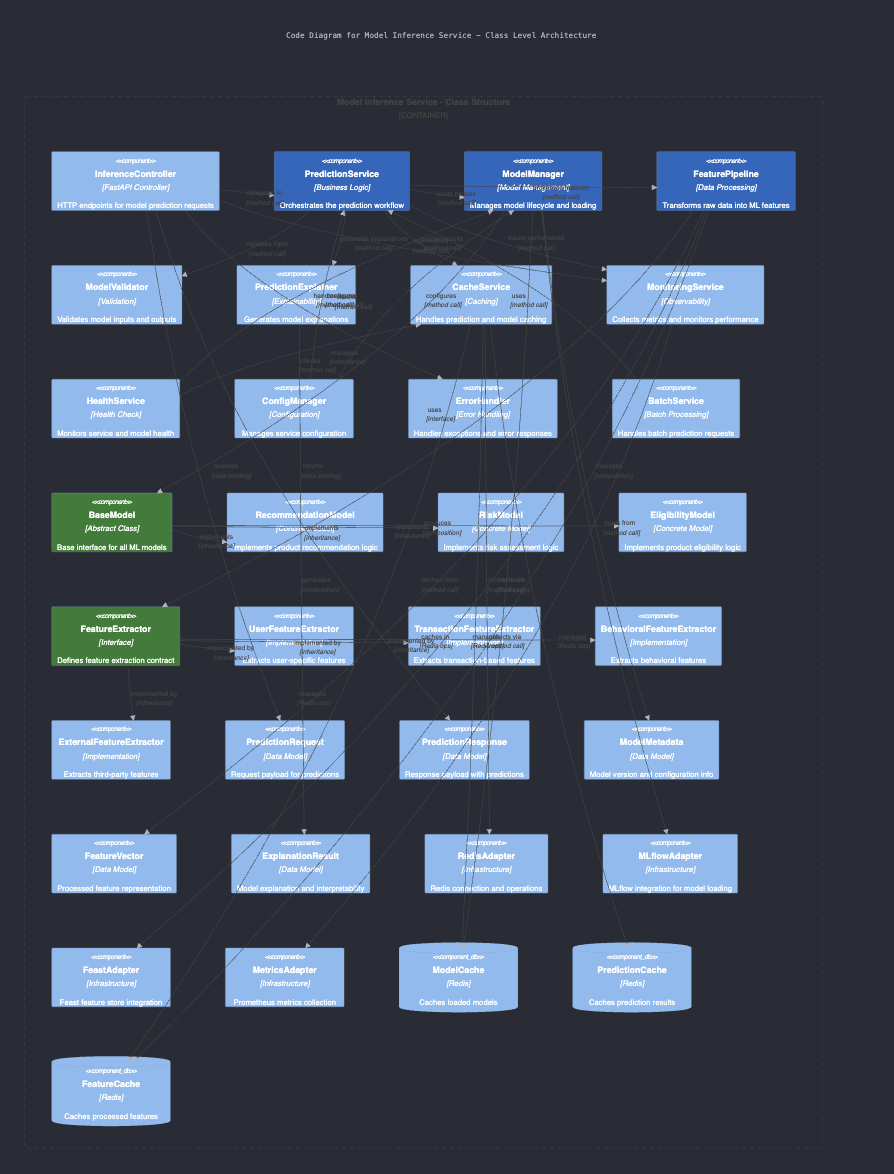
The model started off with a good Context view, describing the main actors and external systems (customers, bank employees, and other data integrations). However, it seemed unable to go deep into the Component and Container views. It managed to outline the main components for the Component view like the banking gateway, model inference service, feature store, and data ingestion pipelines. However, it wasn’t able to describe the intricacies between these components. On the Container view, it didn’t understand the clear distinction between Container view and Code view, which led to the model generating containers as Python classes in an object-oriented fashion (e.g., RecommendationEngine, Preprocessor, RequestValidator, ResponseGenerator, etc.). On the Code view, it nearly duplicated the Container view while providing code snippets for how the implementation should look like. The model was to some extent okay in producing Context and Container views, but it fell short on Component and Code views.
Generated diagram by GPT-4o
2. Claude 4.0 Sonnet (by Anthropic)
The model did a better job at breaking down the problem into abstractions and layers based on the C4 model. It first identified the key actors in the Context view and then decomposed the Container view into 4 regions of deployable containers:
- APIs
- ML pipelines
- Data layer
- Infrastructure
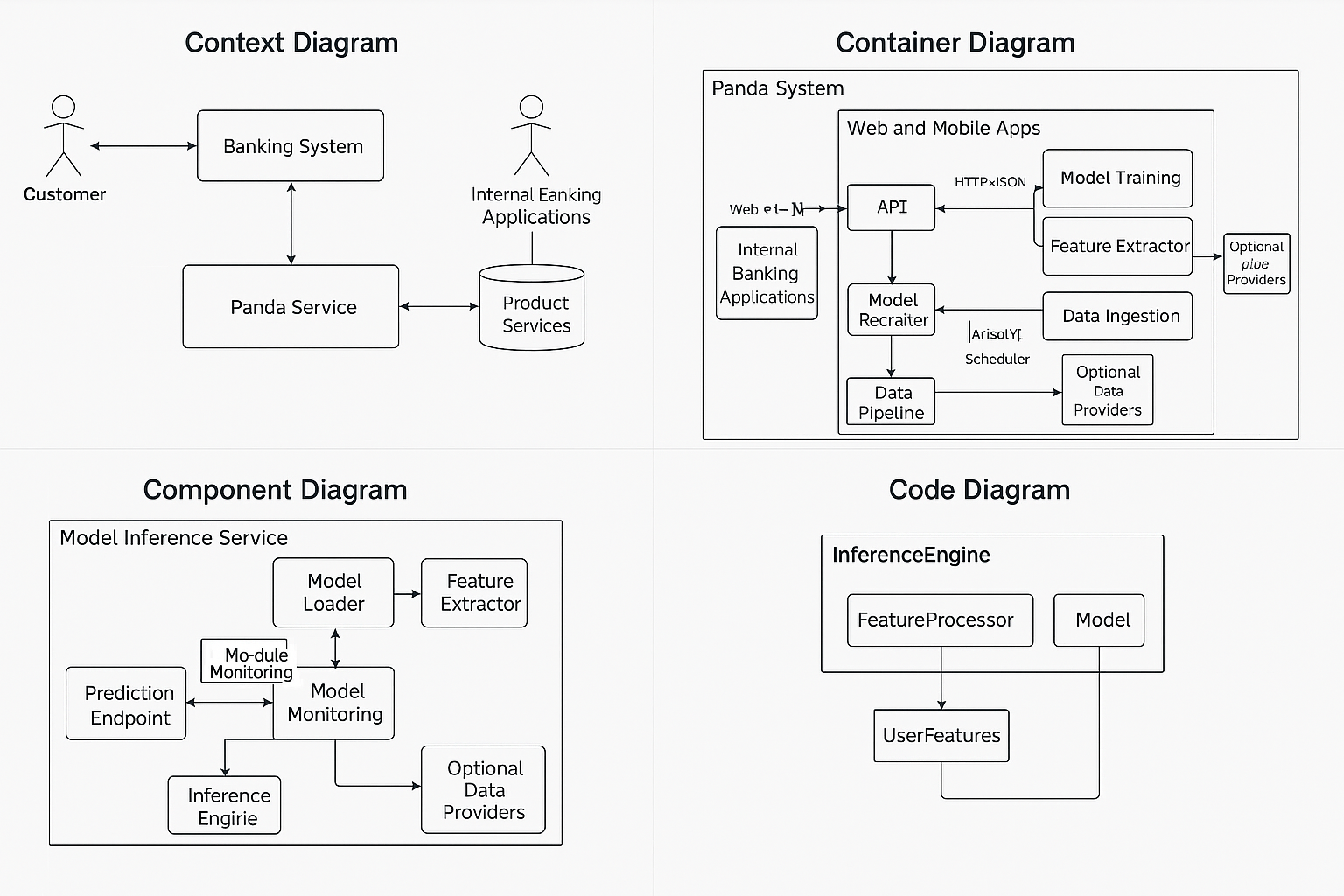
It designed the Component view using the classical Controller-Service-Repository pattern, and expanded on the Code view using common design patterns with heavy emphasis on object-oriented design. The model was also confused between Component and Code views, however it did a better job than GPT-4o, and managed to arrive at an actual diagram.
Generated by Claude 4.0 Sonnet
3. Sonar (by Perplexity)
The model failed to design a mature version of C4 diagrams. The diagrams it produced were very high-level, too simple (black boxes and arrows), with a myriad of incoherent symbols. Its approach to problem decomposition was different from what the other models did. It overindexed on the system view by identifying all possible actors of the system (bank employees, data analysts, data scientists, etc.). The model did not emphasize key concepts or technologies when designing the Container view. It mentioned generic solutions like REST/gRPC for APIs, batch or periodic model training, etc. The model was not able to produce an end-to-end design with specific tradeoffs. The model produced a nearly identical solution for Component/Code views compared to the other models. It mentioned high-level concepts like inference engine, authentication layer, model loader, and data processor. It double-clicked on these concepts again in the Code view, representing them as code classes (i.e., InferenceEngine instead of inference engine).
The model also didn’t seem to understand the difference between Component view and Code view, so it replicated the response, but in a format that seems more code-readable.
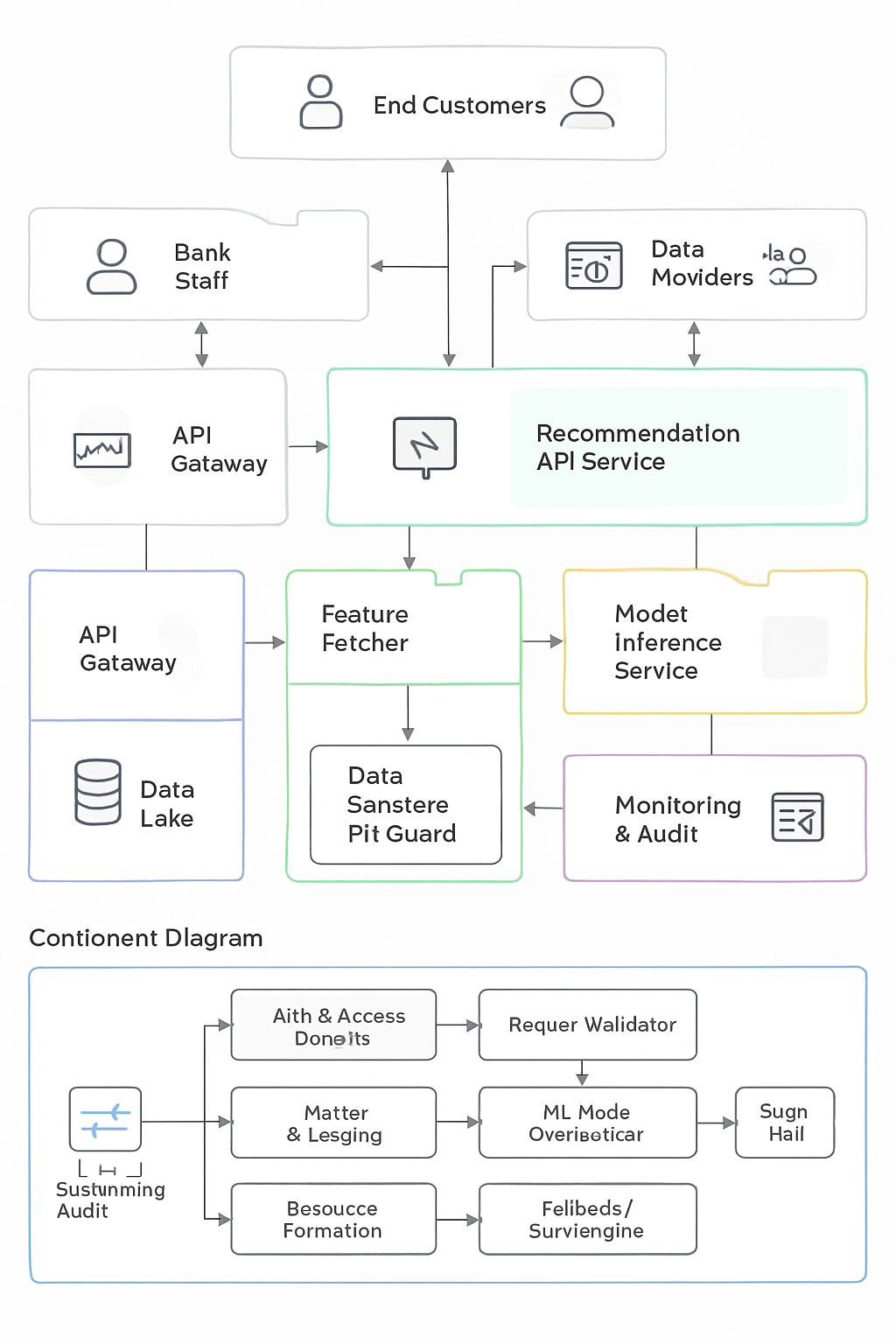
Generated by Sonar
4. Grok 3 (by xAI)
The model performed as poorly as GPT-4o, fixating on the Code diagram. It focused on explaining how the classes will interact with each other, providing snippets of Python code showing how the implementation details would look. With follow-up prompts, the model was able to design some abstract components like DataProvider, CoreBankingService, but it still failed to capture Context, Component, and Container views. It managed to describe key technologies for model and data storage, but was unable to visualize them into a complete diagram.
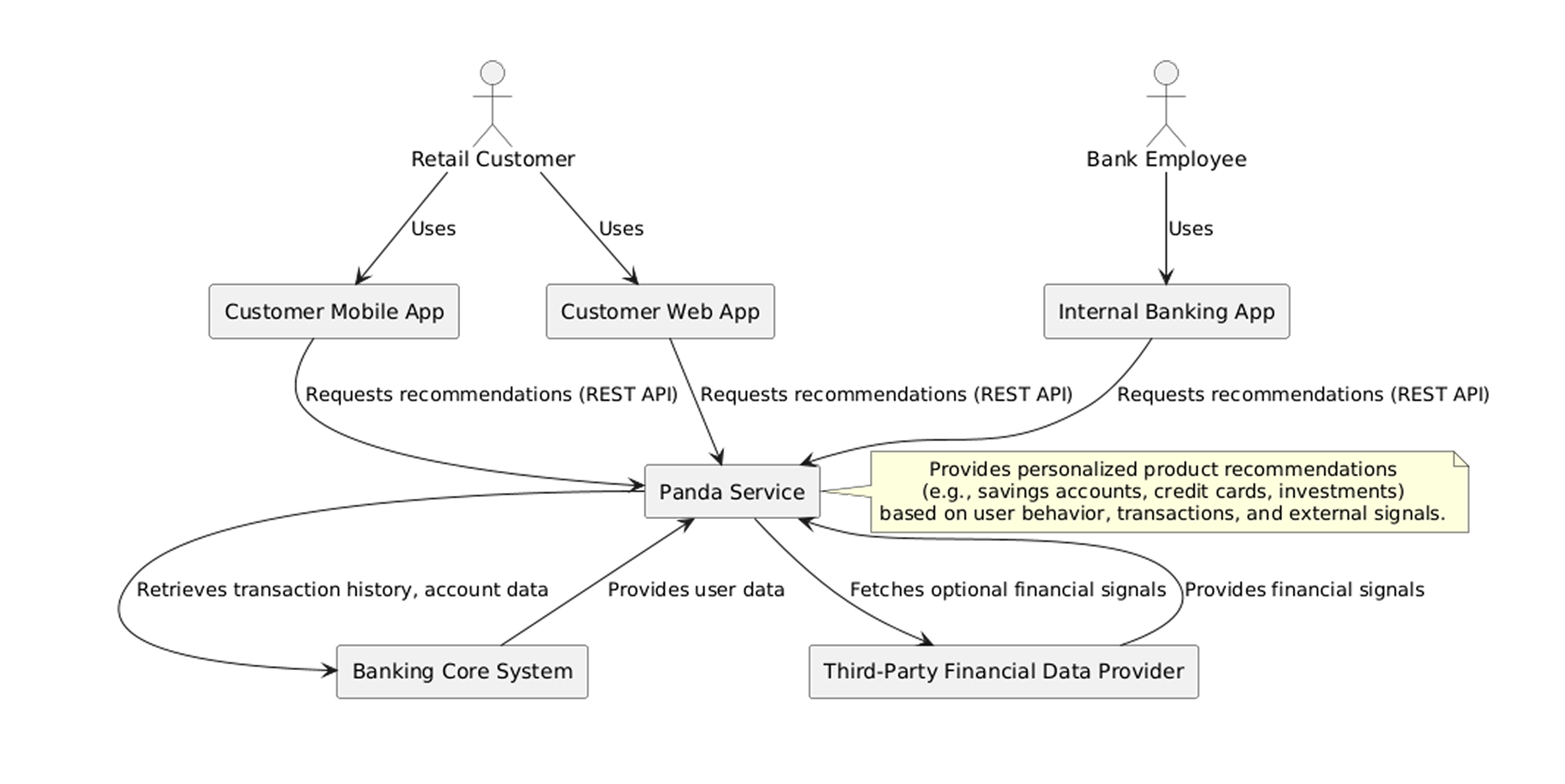
Generated by Grok 3
Conclusion
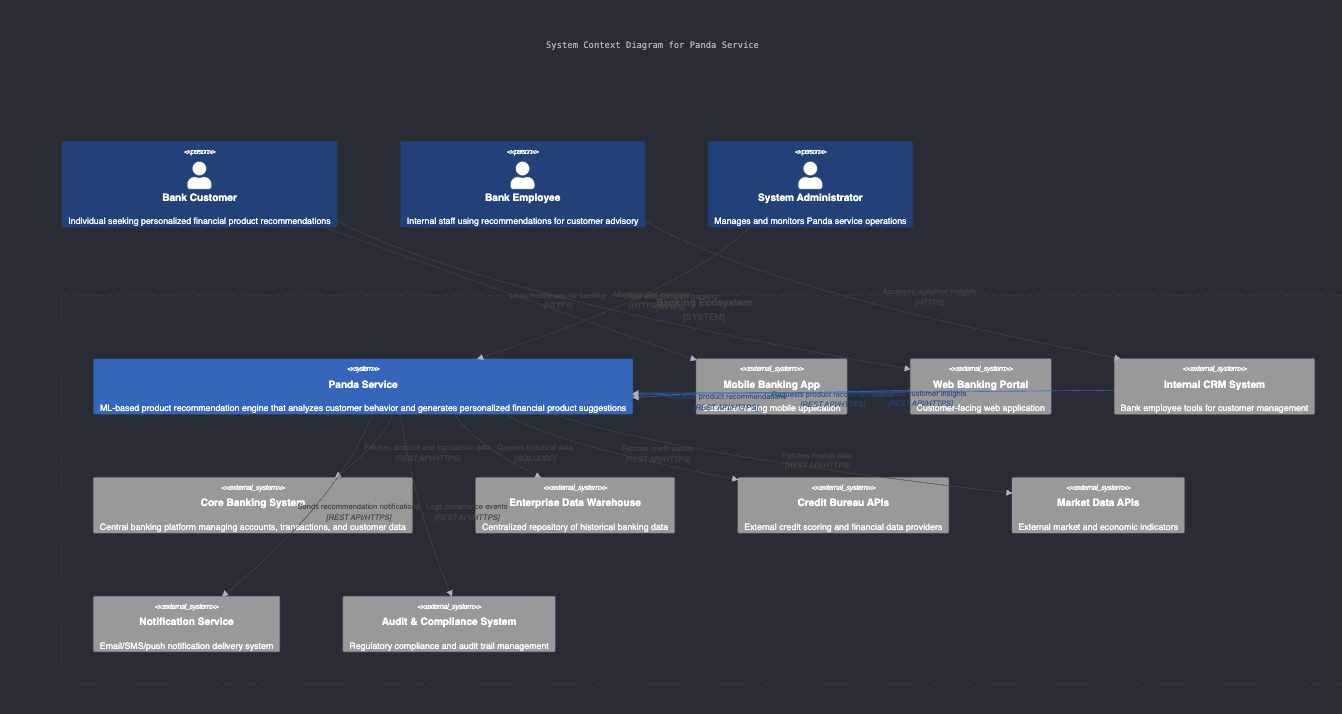
Claude 4.0 Sonnet (by Anthropic) is the winning candidate for producing C4 diagrams. 🏆 The generated diagrams are still not 100% clear for usage, but the model seems to be going in the right direction.
Grok3 and GPT-4o were equally bad. Sonar was okay at basic designs, probably useful for much smaller prototypes. Overall, these LLMs aren’t yet mature enough to produce C4 diagrams of a real-world architecture. They can quickly generate some templates or cookie-cutter designs for software architects to build on top of. However, they are not good enough to be used as a reference.
Here are the generated C4 diagrams by Claude 4.0 Sonnet 👀

Context View
Container View
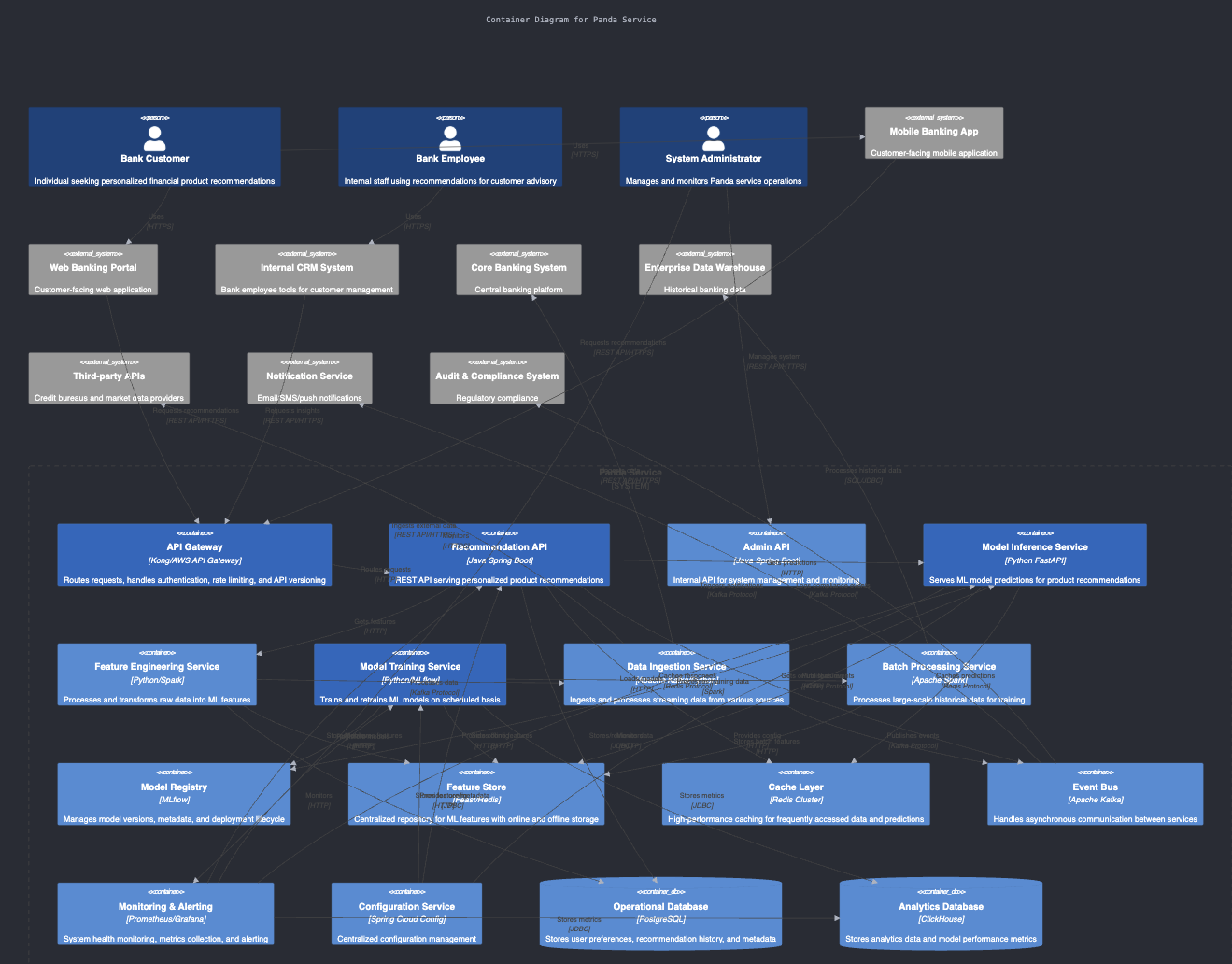
Component View
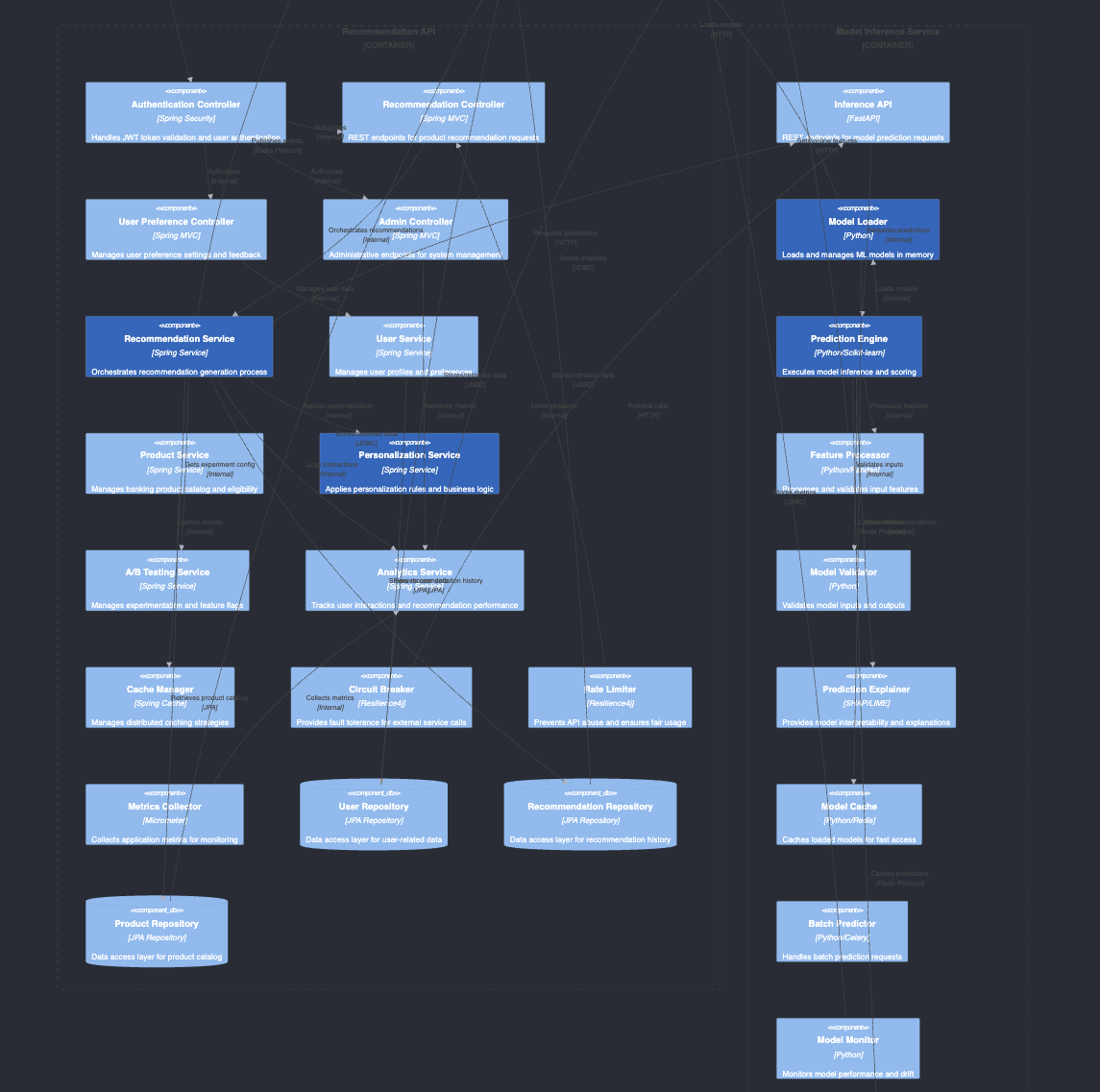
Code View