
📝 Introduction
In this post, we’ll design ChatGPT, an AI-powered conversational system that allows users to interact with large language models (LLMs) through natural language. We’ll approach this as software architects and create four hierarchical diagrams: Context, Container, Component, and Code (not familiar with these? Read this).
Each diagram will be annotated to explain the key building blocks and responsibilities, and we’ll highlight how users interact with the system by visualising data flow using IcePanel Flows.
We’ll start by defining the scope of the system through its functional requirements (what the system does) and non-functional requirements (the qualities it should have). From there, we’ll progressively go through each layer of the C4 model to build the overall architecture.
You can view the final architecture at this link: https://s.icepanel.io/DWnaysJ3cbCQqg/sOie
🔎 Scope
ChatGPT’s core functionality consists of two requirements:
- Users should be able to send prompts and receive streaming responses from LLMs.
- Users should be able to save, load, and search through previous chat histories.
For non-functional requirements, the system should be:
- Availability >> consistency, expected ~10 million daily active users (DAU).
- Highly scalable. Chat users might peak at 10k-20k/sec calls to the model.
- Low latency, users should expect first tokens in ~500 ms and complete responses in ~3 seconds.
- Rate limiting. Users are allowed to send at most 60 requests/min.
Let’s start with the first diagram, Context.
Level 1 - Context
The Context layer defines the actors and external systems ChatGPT depends on. We have one actor and one external system:
- User: End user who chats to ChatGPT through mobile or web.
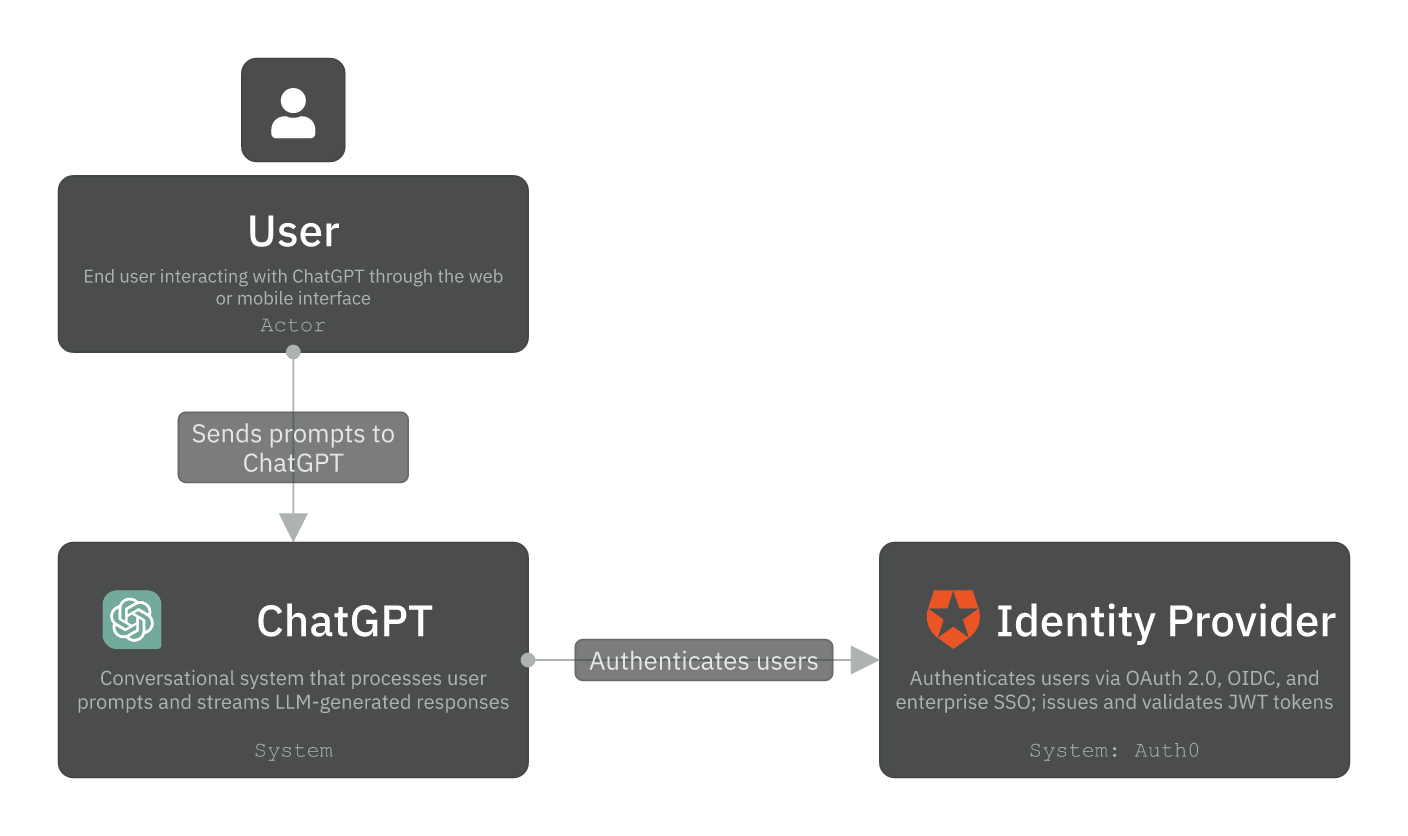
- Identity Provider (Auth0): Provides federated authentication and single sign-on (SSO) capabilities, allowing users to authenticate using their existing social media or enterprise accounts. Our system receives verified identity tokens and uses them to create or authenticate user sessions without handling passwords directly.
Other external systems can be integrated (e.g., Payment Provider like Stripe, but we’ll leave it outside of scope). The more detailed design comes next, the Container diagram.
Level 2 - Container
The Container layer models independently deployable applications, services, and data stores. In this scope, we’ll design ChatGPT using a microservices architecture to independently scale certain workloads and provide high availability and performance (as defined in non-functional requirements).
Our system is composed of the following Containers:
- Completion Service (EC2): The core service responsible for taking a conversation history (a list of messages) as input and generating a context-aware AI response.
- Worker Pool (ECS - Autoscaling): Pool of inference workers that execute LLM requests through the model proxy based on model type, and stream generated tokens back to the Completion service in real time.
- Model Proxy (EC2): An intelligent router for multi-model API endpoints.
- Model API (EC2 GPU-optimised): EC2 machines pre-loaded with LLM weights (e.g., GPT-4, GPT-3.5, or other LLMs) and streams generated tokens back to caller.
- Conversation Service (EC2): A microservice for managing conversation state and retrieving and searching in chat histories.
In this architecture, we use the following technologies:
- AWS API Gateway: A secure entry point for all API requests coming from the frontend. Responsible for routing incoming requests and managing HTTP streaming (SSE) for real-time response delivery.
- Rate Limiter (Redis): A fast in-memory cache for tracking per-user rate limits.
- Elasticsearch Cluster: A search engine for full-text search and retrieval of documents (chat history in this example).
- DynamoDB: A NoSQL document store for persisting chat histories and metadata.
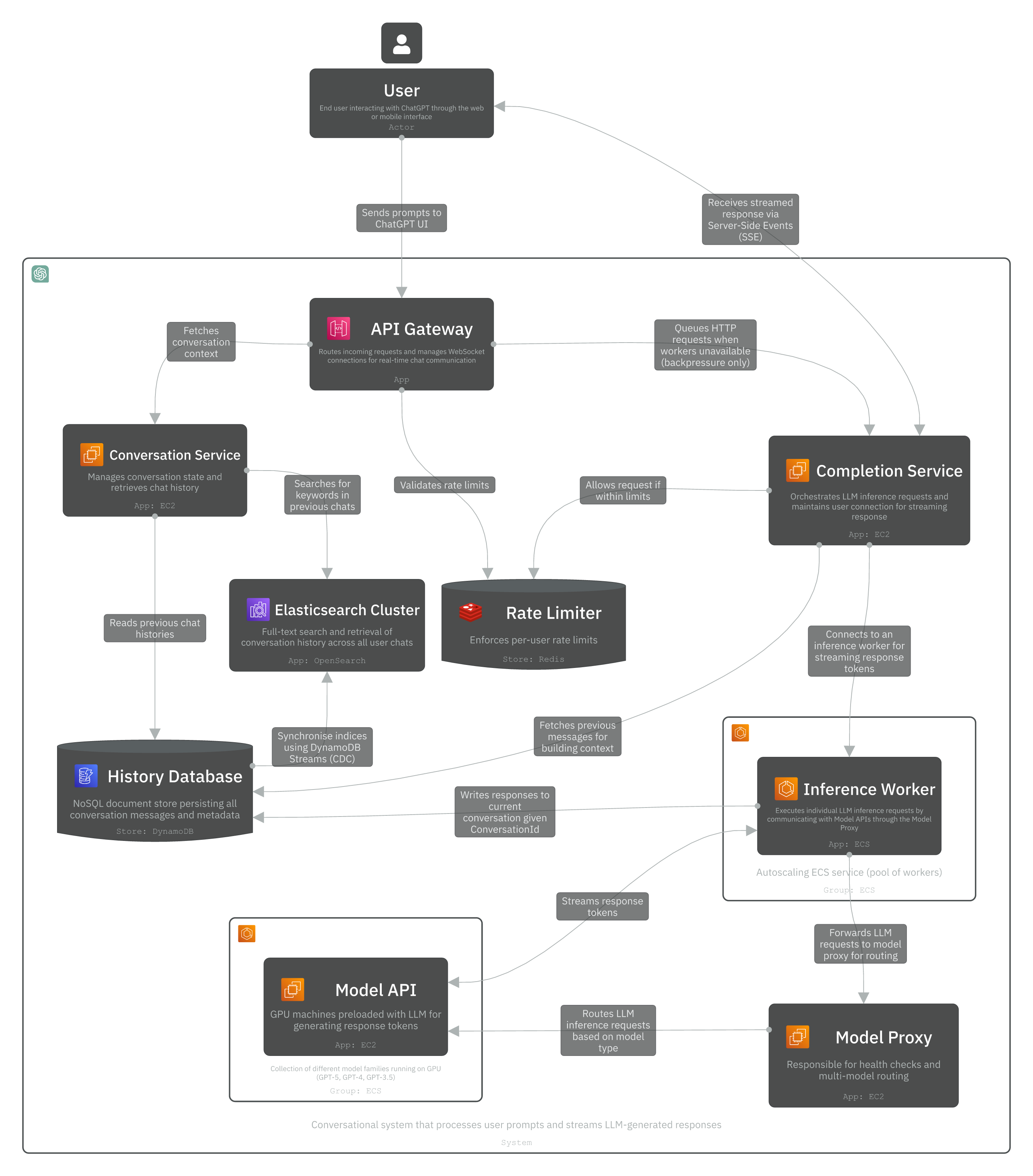
On a high-level, the system works as follows.
The user connects to ChatGPT through the web (chatgpt.com) or mobile. They send a prompt to start a new chat with the backend server. Their requests translate to a POST request (/completions/create) with the user’s prompt, selected model, and other metadata in the payload. The backend server receives this request and routes it to the appropriate model infrastructure (GPU servers), which processes the prompt and streams the generated response back to the user. This response flows through the same path in reverse, from the model servers back through the backend API, which formats and delivers the text incrementally to the UI using Server-Sent Events (SSE), allowing the user to see the LLM’s response appear in real-time as it’s being generated. The user prompt can be modelled in a body request like below:

For more examples, check out OpenAI’s API reference: https://platform.openai.com/docs/api-reference/responses/create
We’ve designed two primary data flows using IcePanel. Check out these flows and play them step by step to see how our system works.
Flow 1: Send a prompt to ChatGPT
Complete flow: https://s.icepanel.io/DWnaysJ3cbCQqg/vPHL
On a high-level,
- User sends prompt via an HTTP POST
- API Gateway validates rate limits
- Completion Service acquires a worker and starts inference
- Tokens stream back to the user via SSE
- Response is persisted to DynamoDB
Flow 2: Find older chat and send a new prompt
Complete flow: https://s.icepanel.io/DWnaysJ3cbCQqg/0Oj7
On a high-level,
- User sends search keywords to find a previous chat.
- Conversation Service queries Elasticsearch for full-text search.
- Chat history is fetched and displayed to the user.
- User sends a new prompt with full conversation context.
- (Flow 1) repeats.
HTTP Streaming and Server-Sent Events (SSE)
When a client sends an HTTP POST request to the Completion API endpoint, the server keeps the response open and streams partial results as they are produced. This is implemented using Server-Sent Events on top of HTTP, which uses a special header (Transfer-Encoding: chunked) that tells the client the data will be streamed into a set of chunks. As tokens are generated by the model, they flow immediately through the system (Model API → Worker → Completion Service → Client) and are flushed to the HTTP response stream. This enables low time-to-first-token (hundreds of milliseconds) and significantly improves latency, as users can start reading the response while the model is still generating it. This is how systems like ChatGPT provide a real-time chatting experience to the user (docs).
Quick note: Some system design readers might suggest using WebSockets (WS) instead of SSE when designing ChatGPT, since WS is a bidirectional protocol commonly used in chat systems like WhatsApp. However, WS introduces significant complexity that requires specialised infrastructure to route and maintain millions of concurrent live user connections. For the scope of this design, that complexity isn’t necessary. One-directional HTTP streaming from the backend is good enough to solve this problem.
Level 3 - Component
In the C4 model, a component is a grouping of related modules encapsulated behind a well-defined interface. Let’s look at the Components in ChatGPT.
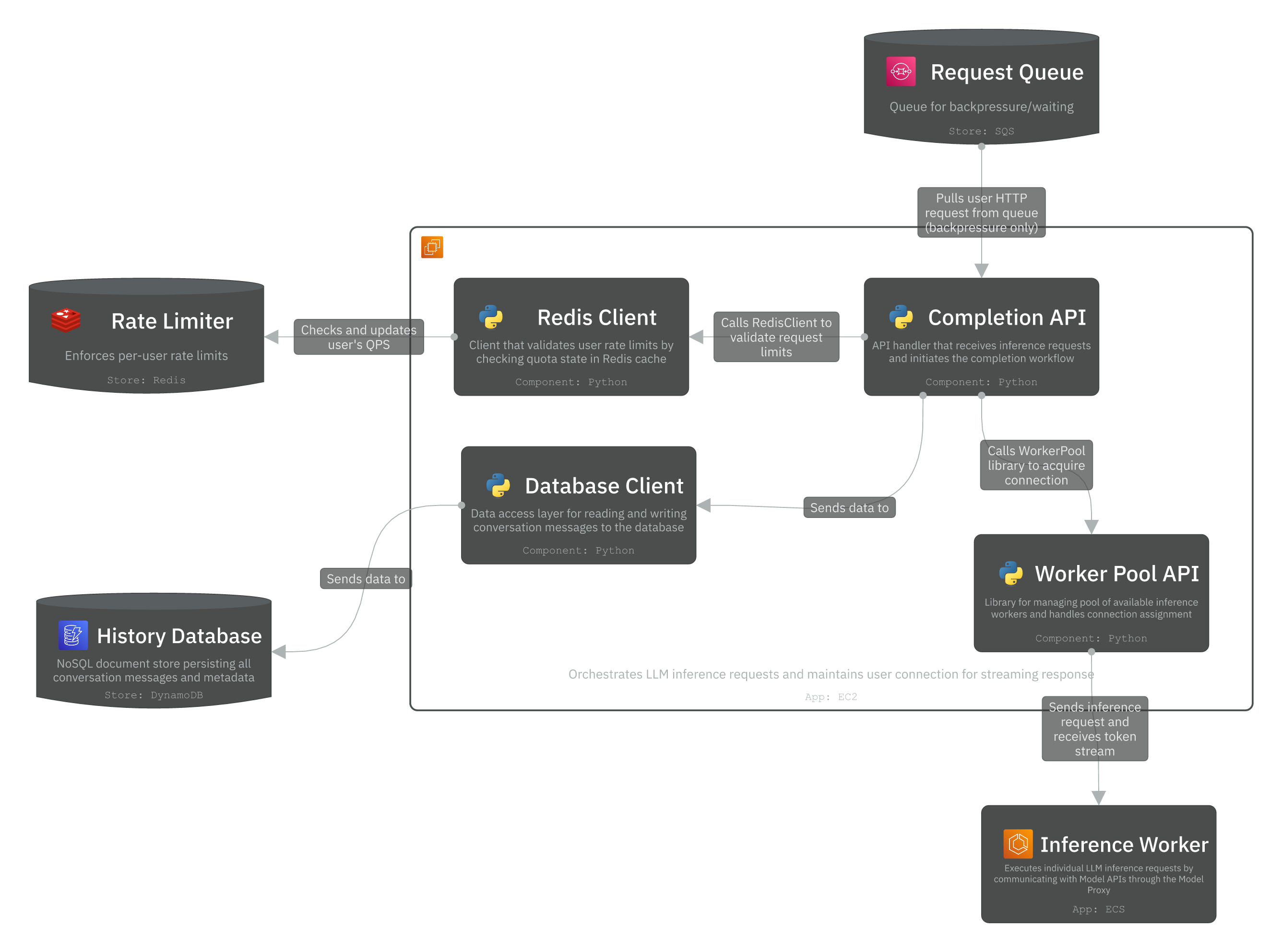
1. Completion Service
This service orchestrates the complete LLM inference lifecycle. When a user sends a chat completion request, the Completion API first validates rate limits via the Redis Client. Once approved, the Worker Pool API acquires an available worker from the pool based on the requested model type (GPT-4, GPT-3.5, etc.). These tokens are immediately streamed back through the API Gateway to the user, creating the real-time chat experience.
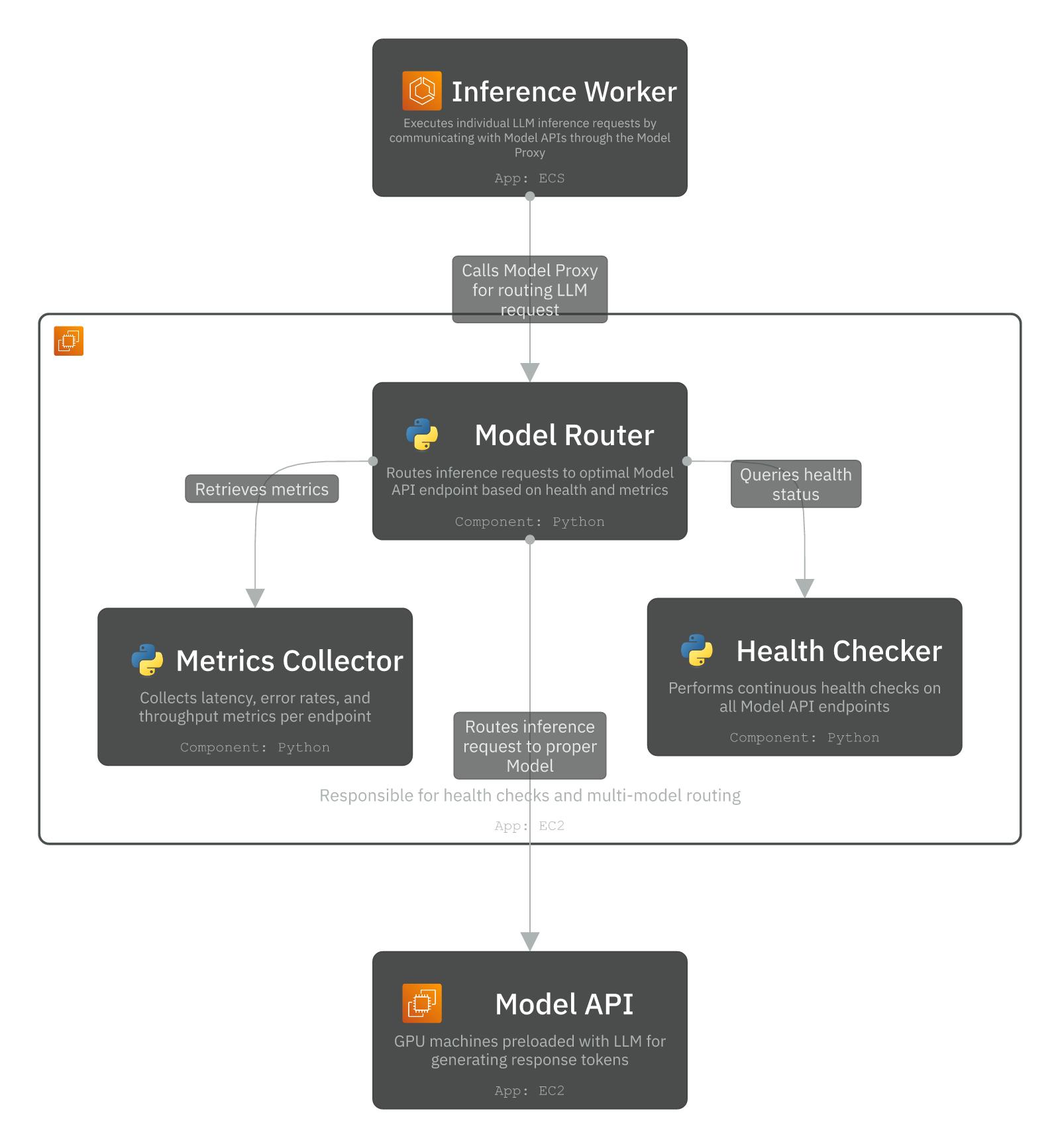
2. Model Proxy Service
The Model Proxy acts as an intelligent routing layer between workers and Model APIs. The Model Router selects the optimal API endpoint by consulting the Health Checker for endpoint status and the Metrics Collector for latency data. It calculates a routing score combining health, latency, and current load to choose the best endpoint. All requests pass through the Circuit Breaker, which monitors failure rates and prevents cascade failures by temporarily blocking requests to unhealthy endpoints. This architecture ensures requests are always routed to the fastest, most reliable Model API instances across multiple regions.
3. Conversation Service
The Conversation Service manages chat history retrieval and search. When a user requests their conversation history, the Conversation API first queries the Elasticsearch Client for fast full-text search across all messages. For direct conversation retrieval, the History Repository fetches data from DynamoDB, which serves as the source of truth. New messages are persisted to DynamoDB and asynchronously synced to Elasticsearch via DynamoDB Streams for eventual consistency (which is acceptable in this case).
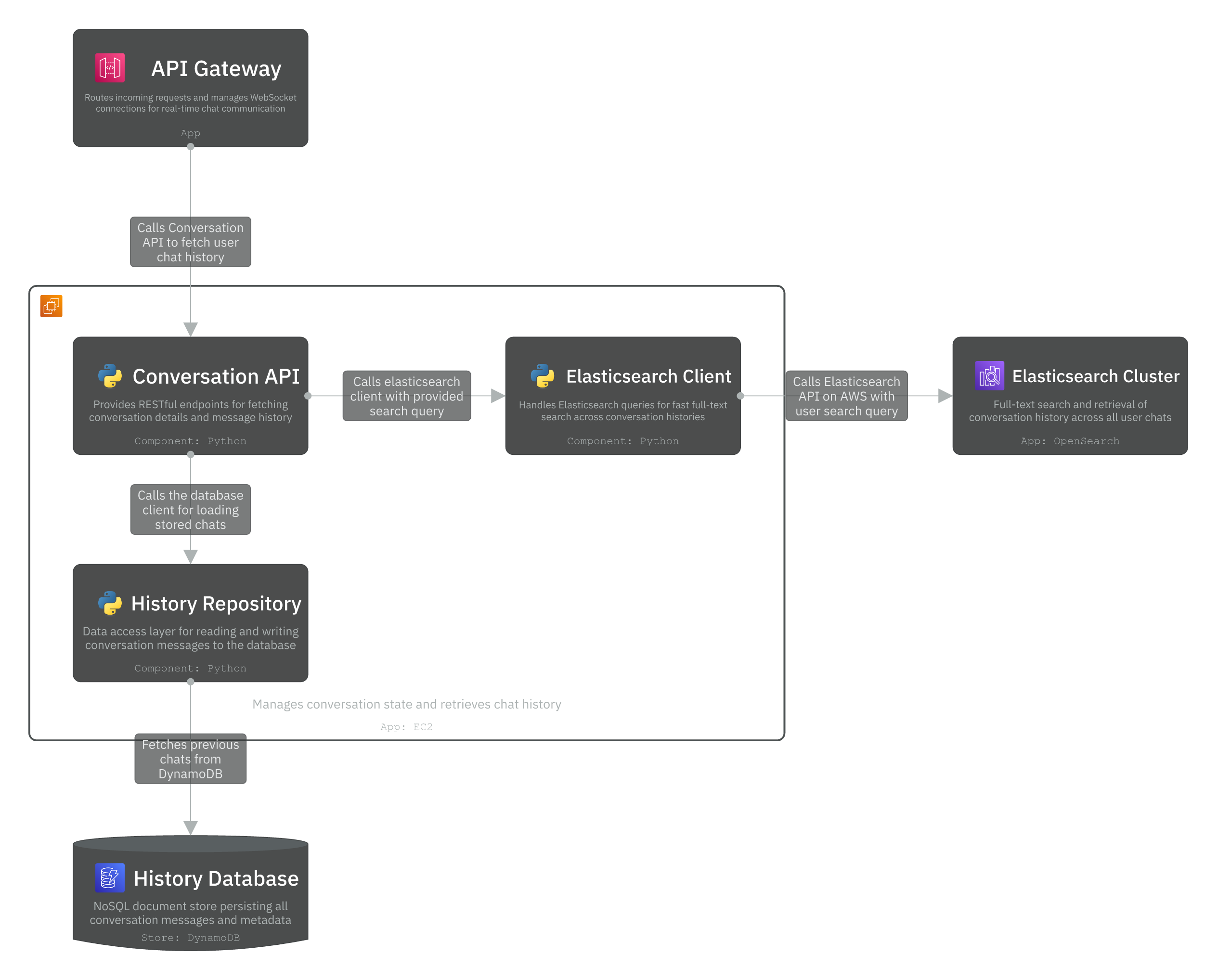
Let’s go one level deeper with the source code in the Code layer.
Level 4 - Code
This is where we can view implementation details at the code level. At this level, we focus on code structure rather than diagrams. We’ll briefly go over two Components: Completion and Conversation.
Code Classes in Completion Service
This component orchestrates LLM inference requests by managing the complete lifecycle from rate limit validation to streaming response delivery. The Completion API provides RESTful endpoints for initiating chat completions. The RedisClient validates user rate limits by checking global user quotas (60 requests per minute) stored in Redis before allowing requests to proceed. The WorkerPoolAPI manages the pool of available workers, handles load balancing, and acquires connections for inference requests.
Completion API
RESTful endpoints for chat completion requests
- POST /v1/chat/completions - Initiate a new chat completion
- POST /v1/chat/completions/:requestId/cancel - Cancel an ongoing completion request
Redis Client
Manages per-user rate limiting and validation
- isAllowed(userId) - Validates if user is within QPS and concurrent generation limits
- updateUsage(userId, tokenCount) - Records user request and token usage
Worker Pool API
Manages worker pool and connection lifecycle
- acquire(modelType, priority): Worker - Acquires available worker from pool based on model requirements
- release(workerId) - Returns worker to available pool after request completion
Code Classes in Conversation Service
This component manages conversation state and retrieves chat history for LLM context. The Conversation API class exposes RESTful endpoints for fetching user conversations and chat history. The API first queries Elasticsearch for fast full-text search across conversation histories before falling back to the History Repository for direct database access. The Elasticsearch client handles all interactions with the Elasticsearch cluster, providing efficient search capabilities. The History Repository serves as the data layer for fetching conversation messages and metadata from the History Database (DynamoDB).
These classes have roughly the following methods:
Conversation API
RESTful endpoints for conversation and chat history management
- GET /v1/conversations/:conversationId - Retrieve conversation details and complete message history.
- GET /v1/conversations/:conversationId/messages?limit&cursor - Retrieve paginated messages for a conversation.
- POST /v1/conversations/search - Search for specific keywords in past conversations
Elasticsearch Client
Manages Elasticsearch interactions for fast conversation search
- search(userId, query, filters) - Full-text search across all user conversations
- getMessages(conversationId, limit, cursor) - Retrieves messages from Elasticsearch index
History Repository
Data access layer for DynamoDB conversation storage
- getConversation(id) - Fetches chat history given conversationId
- appendMessage(conversationId, role, content, tokens) - Saves message given conversationId
Conclusion
In this post, we designed an AI chat system like ChatGPT using the C4 model on IcePanel. We began with the core requirements and modeled the system from the top down, starting with the Context layer, followed by the Container, Component, and finally the Code layer.
If you’d like to see more design deep dives, check out:
- https://icepanel.io/blog/2025-10-20-design-ticketmaster-using-icepanel
- https://icepanel.io/blog/2025-11-18-design-youtube-using-icepanel
- https://icepanel.io/blog/2025-12-18-design-ebay-using-icepanel
Let us know which system you’d like to see modeled next on IcePanel!
📚 Resources
- https://aws.amazon.com/api-gateway
- https://aws.amazon.com/dynamodb
- https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Streams.html
- https://platform.openai.com/docs/api-reference/chat-streaming
- https://platform.openai.com/docs/models
- https://redis.io/open-source
- https://aws.amazon.com/microservices
- https://aws.amazon.com/what-is/elasticsearch
